
Контейнеризация. NameSpaces
Для того, чтобы понимать что такое контейнеризация и как она работает, необходимо разбираться в 2 понятиях Операционной Системы (чаще всего Linix): Cgroup и Namespace. В рамках этой статьи мы разберем что такое Namespace. Так же в рамках этой статьи мы создадим что-то очень похожее на реальный контейнер руками. По крайней мере мы поймем как это работает, что немаловажно
Общая информация
Если Cgroup’ы позволяют контролировать ресурсы, доступные процессам, то Namespace отвечают за видимость и доступность различных компонентов для процесса.
Есть несколько типов NameSpace:
- Система разделения времени Unix (UTS)
- Идентификаторы процессов (PID)
- Точки монтирования (MNT)
- Сеть (NET)
- Идентификаторы пользователей и групп (USER)
- Обмен информации между процессами (IPC)
- Контрольные группы (CGROUP)
Запущенные процесс всегда относится к одному пространству имен каждого типа.
Рассмотрим каждый тип по отдельности
Система разделения времени Unix (UTS). Или же Unix Time-Sharing
Хоть этот Namespace и называется timesharing его используют для разделения хост-имени процесса и сервера, на котором этот процесс запущен.
Узнать хост-имя можно с помощью команды hostname, и если мы запустим эту команду внутри контейнера - мы увидем рандомно сгенерированный набор символов.
❯ docker run -d nginx
679a476d14dca1636ece25a25aee7a7e17dfa7186452b2103268d77ace3742e5
❯ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
679a476d14dc nginx "/docker-entrypoint.…" 14 seconds ago Up 13 seconds 80/tcp xenodochial_kilby
❯ docker exec -it xenodochial_kilby hostname
679a476d14dc
Для управления namespace для процессов можно использовать команду unshare при создании процесса.
Давайте для примера запустим новый процесс для оболочки sh с параметром unshare, в котором укажем, что для нашего процесса используется namespace UTS. При старте этого процесса можно увидеть, что он взял родительский hostname с машины, где этот процесс был запущен. Однако мы можем изменить имя хоста и когда выйдем из процесса увидем, что на сервере hostname не изменился. Это происходит потому что при старте нашего процесса у него было свое пространство имен не связанное с сервером, где этот процесс был запущен.
❯ hostname
ubuntu20
❯ sudo unshare --uts sh
# hostname
ubuntu20
# hostname test
# hostname
test
# exit
❯ hostname
ubuntu20
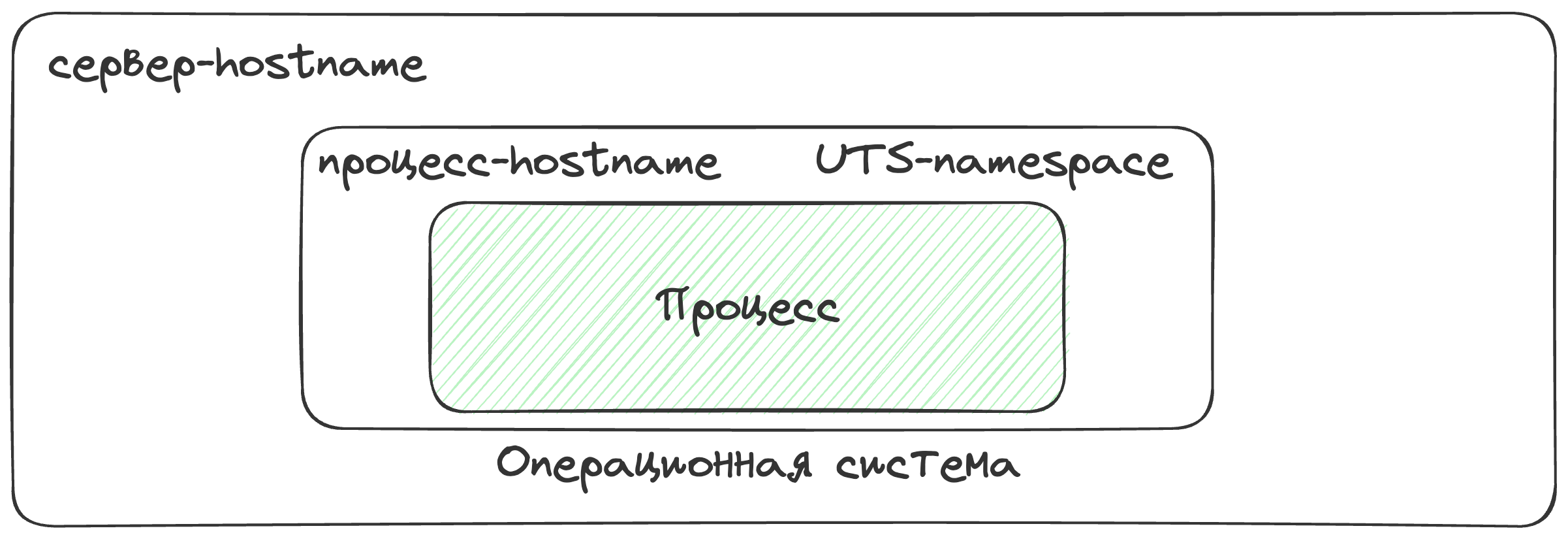
Изоляция идентификаторов процессов
Запуская контейнер внутри него мы можем видеть только те процессы, которые используются в этом контейнере:
❯ docker run -d busybox sleep 1000
71d85cdb6044d7ba14731d283c500b3ea1ce53fbf1d2fd43a2150e3acb7b0afe
❯ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
71d85cdb6044 busybox "sleep 1000" 2 seconds ago Up 1 second bold_dhawan
❯ docker exec -it bold_dhawan ps
PID USER TIME COMMAND
1 root 0:00 sleep 1000
7 root 0:00 ps
Давайте попробуем сымитировать такое же поведение с помощью уже известной нам команды unshare:
❯ sudo unshare --pid sh
# ps
PID TTY TIME CMD
8437 pts/0 00:00:00 sudo
8438 pts/0 00:00:00 bash
9416 pts/0 00:00:00 sudo
9417 pts/0 00:00:00 sh
9418 pts/0 00:00:00 ps
# ps
sh: 2: Cannot fork
# ps
sh: 3: Cannot fork
# ps
sh: 4: Cannot fork
#
Внутри процесса sh мы смогли выполнить только одну команду, а все последующие упали с ошибкой Cannot fork. Это происходит по причине того, что 1ым процессом в нашем новом пространстве имен был первый выполненный нами процесс ps и когда этот процесс был завершен - ядро linux’а сразу ограничило функциональность для нашего пространства. Это связано с тем, что linux не любит, когда не существует активного процесса с номером 1, он же init процесс.
Если мы посмотрим иерархию процессов на этом сервере в другом терминале, мы увидем что происходит:
❯ ps fa
8438 pts/0 S 0:00 -bash
9416 pts/0 S 0:00 \_ sudo unshare --pid sh
9417 pts/0 S+ 0:00 \_ sh
Получается, что наш процесс является дочерним процессом sudo. Не unshare, а sudo.
Решается эта проблема с помощью аргумента --fork:
❯ sudo unshare --pid --fork sh
## В другом терминале:
❯ ps fa
PID TTY STAT TIME COMMAND
8438 pts/0 S 0:00 -bash
9535 pts/0 S 0:00 \_ sudo unshare --pid --fork sh
9536 pts/0 S 0:00 \_ unshare --pid --fork sh
9537 pts/0 S+ 0:00 \_ sh
Однако если мы попробуем в нашем namespace посмотреть все процессы - мы увидем все процессы родительской машины:
❯ sudo unshare --pid --fork sh
# ps
PID TTY TIME CMD
8437 pts/0 00:00:00 sudo
8438 pts/0 00:00:00 bash
9535 pts/0 00:00:00 sudo
9536 pts/0 00:00:00 unshare
9537 pts/0 00:00:00 sh
9540 pts/0 00:00:00 ps
Это связанно с тем, как работает команда ps. ps данные для отображения собирает из директории /proc, которая доступна в нашем namespace. Соответсвенно для нашего namespace нам нужна персональная копия директории /proc, в которой будут только те процессы, которые связаны с нашим пространством имен. Таким образом мы плавно перетекаем к следующей настройке.
Изменение корневого каталога (chroot)
Немного переключимся с пространств имен на другой, не менее важный, функционал ОС Linux - chroot. По умолчанию в нашем запущенном процессе доступна вся файловая система нашей машины, однако в контейнерах это выглядит совсем иначе. Запуская контейнер мы видим файловую систему, которая распаковывается из image нашего контейнера, а файловая система хост-машины нам недоступна.
Реализуется такая функциональность благодаря chroot. Все что делает эта команда - меняет корневой каталог на указанный, а все, что находится выше корневого каталога становится недоступным. Происходит это по простой причине - выше корневого каталога подняться невозможно.
Давайте поэксперементируем. Создаем директорию newRoot и пробуем сделать chroot в эту директорию выполнив какую-то команду:
❯ mkdir newRoot
❯ sudo chroot newRoot ls
chroot: failed to run command 'ls': No such file or directory
❯ sudo chroot newRoot bash
chroot: failed to run command 'bash': No such file or directory
Не работает. Логично, ведь выполняя команду в операционной системе Linux - вы исполняете определенный файл, который находится в одном из каталогов, перечисленных в переменной окружения - PATH. Проверить где должен находиться исполняемый файл любой команды можно с помощью команды which. Однако когда мы делаем chroot в нашу новую директорию newRoot командная оболочка считает newRoot - корневой директорией и именно относительно нее пытается найти директории из переменной PATH. У нас же директория newRoot пустая, директории перечисленных в PATH, а тем более исполняемых файлов, нет - соответственно мы получаем ошибку.
Когда мы запускаем контейнер - у нас создается директория, в которой есть все необходимые каталоги, для работы. У разных образов контейнеров иерархия файлов может немного отличаться.
Давайте загрузим себе корневую директорию, которая используется для сборки образа alpine:
❯ mkdir apline
❯ cd alpine/
❯ curl -o alpine.tar.gz https://dl-cdn.alpinelinux.org/alpine/v3.10/releases/aarch64/alpine-minirootfs-3.10.9-aarch64.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2567k 100 2567k 0 0 5568k 0 --:--:-- --:--:-- --:--:-- 5568k
❯ tar xvf alpine.tar.gz
./
./opt/
./lib/
...
...
❯ rm alpine.tar.gz
❯ ls
bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
Теперь у нас есть директория alpine, которая Внутри выглядит как корневой каталог системы.
Пробуем теперь запустить chroot в нашу директорию alpine:
❯ cd ..
❯ sudo chroot alpine sh
# ls
bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
# cat /etc/passwd
root:x:0:0:root:/root:/bin/ash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
news:x:9:13:news:/usr/lib/news:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucppublic:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
man:x:13:15:man:/usr/man:/sbin/nologin
postmaster:x:14:12:postmaster:/var/spool/mail:/sbin/nologin
cron:x:16:16:cron:/var/spool/cron:/sbin/nologin
ftp:x:21:21::/var/lib/ftp:/sbin/nologin
sshd:x:22:22:sshd:/dev/null:/sbin/nologin
at:x:25:25:at:/var/spool/cron/atjobs:/sbin/nologin
squid:x:31:31:Squid:/var/cache/squid:/sbin/nologin
xfs:x:33:33:X Font Server:/etc/X11/fs:/sbin/nologin
games:x:35:35:games:/usr/games:/sbin/nologin
postgres:x:70:70::/var/lib/postgresql:/bin/sh
cyrus:x:85:12::/usr/cyrus:/sbin/nologin
vpopmail:x:89:89::/var/vpopmail:/sbin/nologin
ntp:x:123:123:NTP:/var/empty:/sbin/nologin
smmsp:x:209:209:smmsp:/var/spool/mqueue:/sbin/nologin
guest:x:405:100:guest:/dev/null:/sbin/nologin
nobody:x:65534:65534:nobody:/:/sbin/nologin
Теперь мы можем объединить возможности пространств имен и изменение корневого каталога и решить проблему видимости процессов, которая возникала ранее:
sudo unshare --uts --pid --fork chroot alpine sh
Запуская такую команду мы попадаем в изолированное пространство, однако команда ps возвращает нам пустоту (или ошибку). Связано это с тем, что в нашем новом пространстве нет директории /proc, откуда ps читает информацию.
Монтируем в наше пространство имен псевдофайловую систему proc:
# ps
PID USER TIME COMMAND
# mount -t proc proc proc
# ps
PID USER TIME COMMAND
1 root 0:00 sh
4 root 0:00 ps
Кстати все, что мы проделали можно протестировать и в обратном порядке при работе с контейнерами. Например если у нас уже есть запущенный контейнер, значит файловая система этого контейнера доступна где-то на нашем сервере и мы можем производить с ней манипуляции:
❯ docker run -d nginx
c5cf79611b92c2cf70017eea6bc48078ce04a57df8d2e8963091870fd755b455
❯ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c5cf79611b92 nginx "/docker-entrypoint.…" 2 seconds ago Up 1 second 80/tcp serene_murdock
❯ docker inspect serene_murdock | grep UpperDir
"UpperDir": "/var/lib/docker/overlay2/317405b3c0330695f9b8e21b5bc318b3260898a0f00ac5289c6fb267a63ccefa/diff",
❯ echo "test data" > /var/lib/docker/overlay2/317405b3c0330695f9b8e21b5bc318b3260898a0f00ac5289c6fb267a63ccefa/diff/testFile
❯ docker exec -it serene_murdock bash
root@c5cf79611b92:/# cat testFile
test data
На всякий случай. Так делать плохо. Очень плохо. Единственное для чего я показываю этот функционал - так это для того, чтобы вы наглядно увидели как работают контейнеры!
На самом деле на данном этапе мы уже создали так называемый контейнер.
Я надеюсь полученной информации достаточно, чтобы понять крайне важную вещь, к которой я подвожу уже вторую статью подряд. Контейнер - это всего лишь обычный процесс, созданный в операционной системе Linux, который изолирован с помощью различных пространств имен и ограничен с помощью контрольных групп.
Есть еще некоторые пространства имен, но по ним мы пройдемся очень поверхностно, просто чтобы понимать, что они существуют и зачем используются
Пространства имен монтирования
Крайне нежелательно было бы, если наш контейнер использовал точки монтирования файловых систем хоста, по этому для контейнера можно определить свою точку монтирования и изолировать ее от хостовой с помощью того же chroot’a
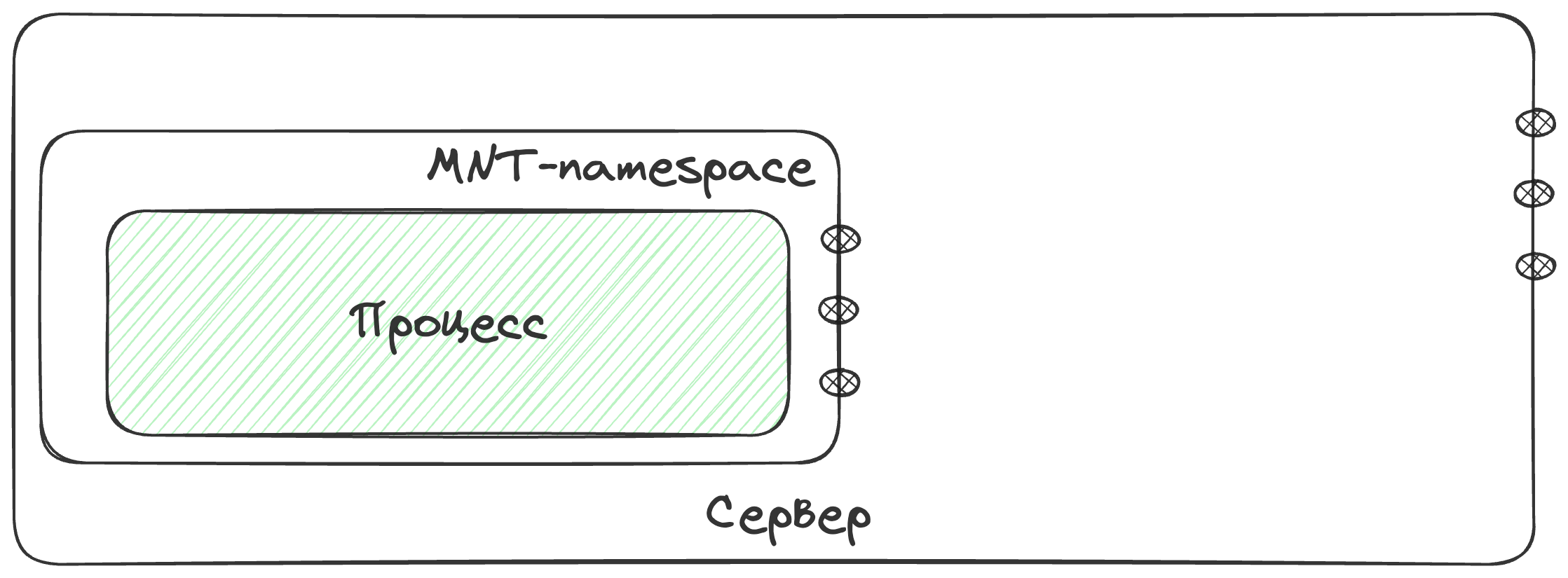
Пространство имен сети
Благодаря пространству имен сети контейнер получает независимое представление сетевых интерфейсов и таблицы маршрутизации
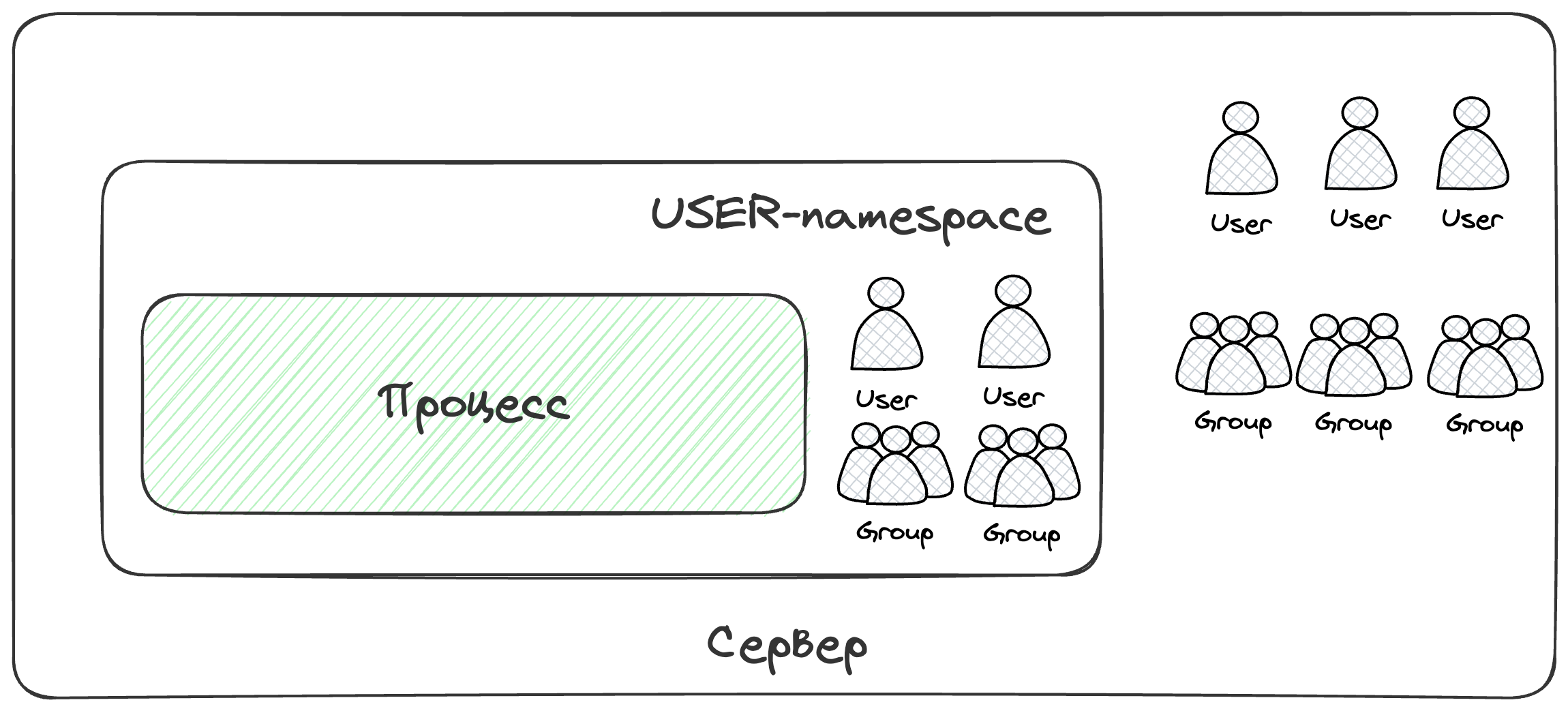
Пространство имен пользователей
Благодаря пространству имен пользователей процессы внутри контейнера получают свое представление об идентификаторах пользователей и групп. Однако данное пространство имен не поддерживается в Kubernetes’e. Есть длинная дискуссия на GitHub на эту тему и даже готовы решения для alpha-тестирования, но пока они небыли зарелижены.
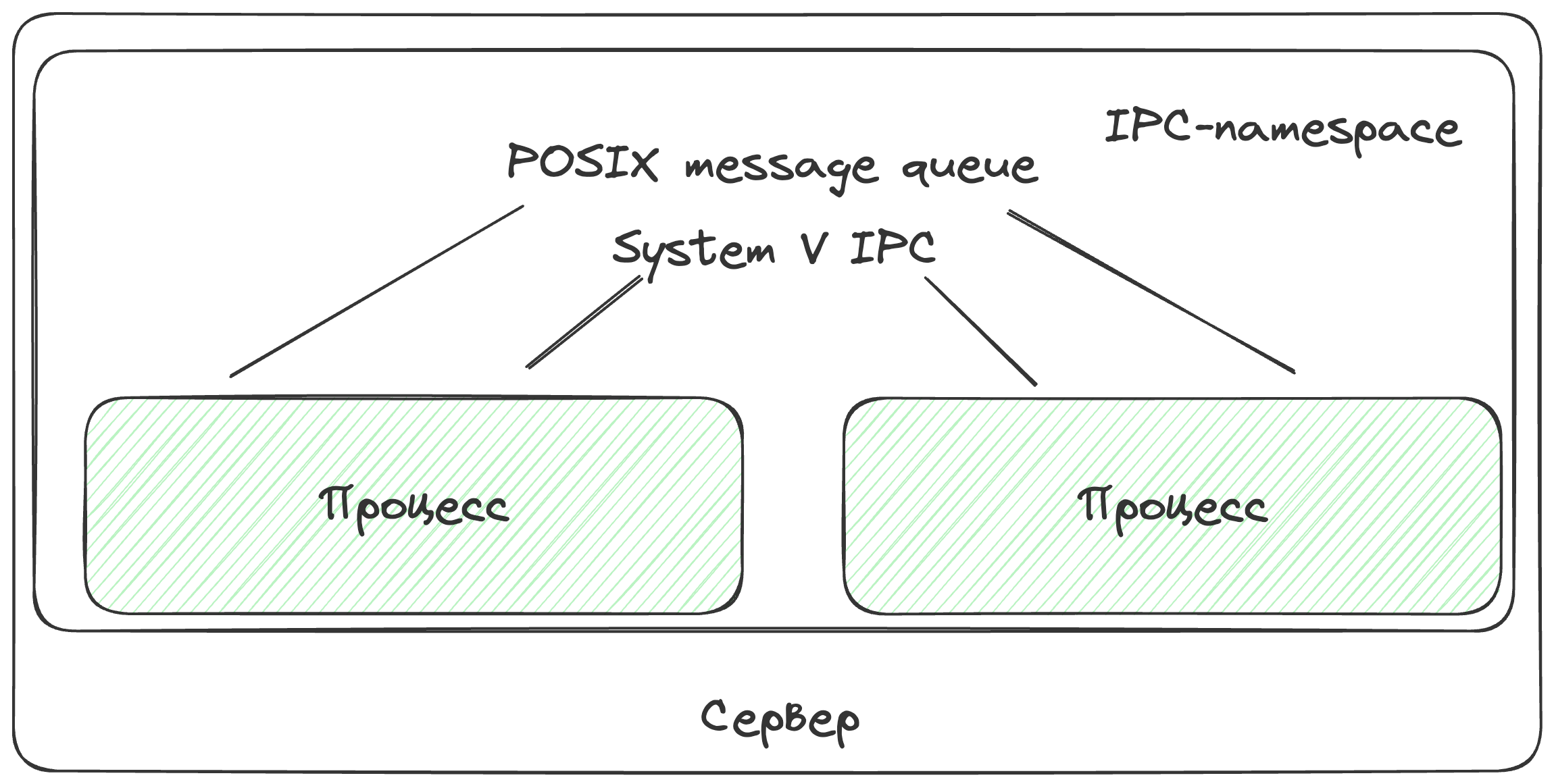
Пространство имен для обмена информацией между процессами
Если, например, 2 контейнера будут входить в одно пространство для обмена информацией - они оба будут иметь доступ к разделяемой области памяти либо очереди сообщений.
Однако это нежелательный функционал для работы контейнеров. В рамках Kubernetes’а такая возможность присутствует только для контейнеров, описанных в рамках одного pod’а.
Пространство имен контрольных групп
По факту не дает процессу видеть контрольных группы хост машины, которые не связанны с конкретно этим процессом
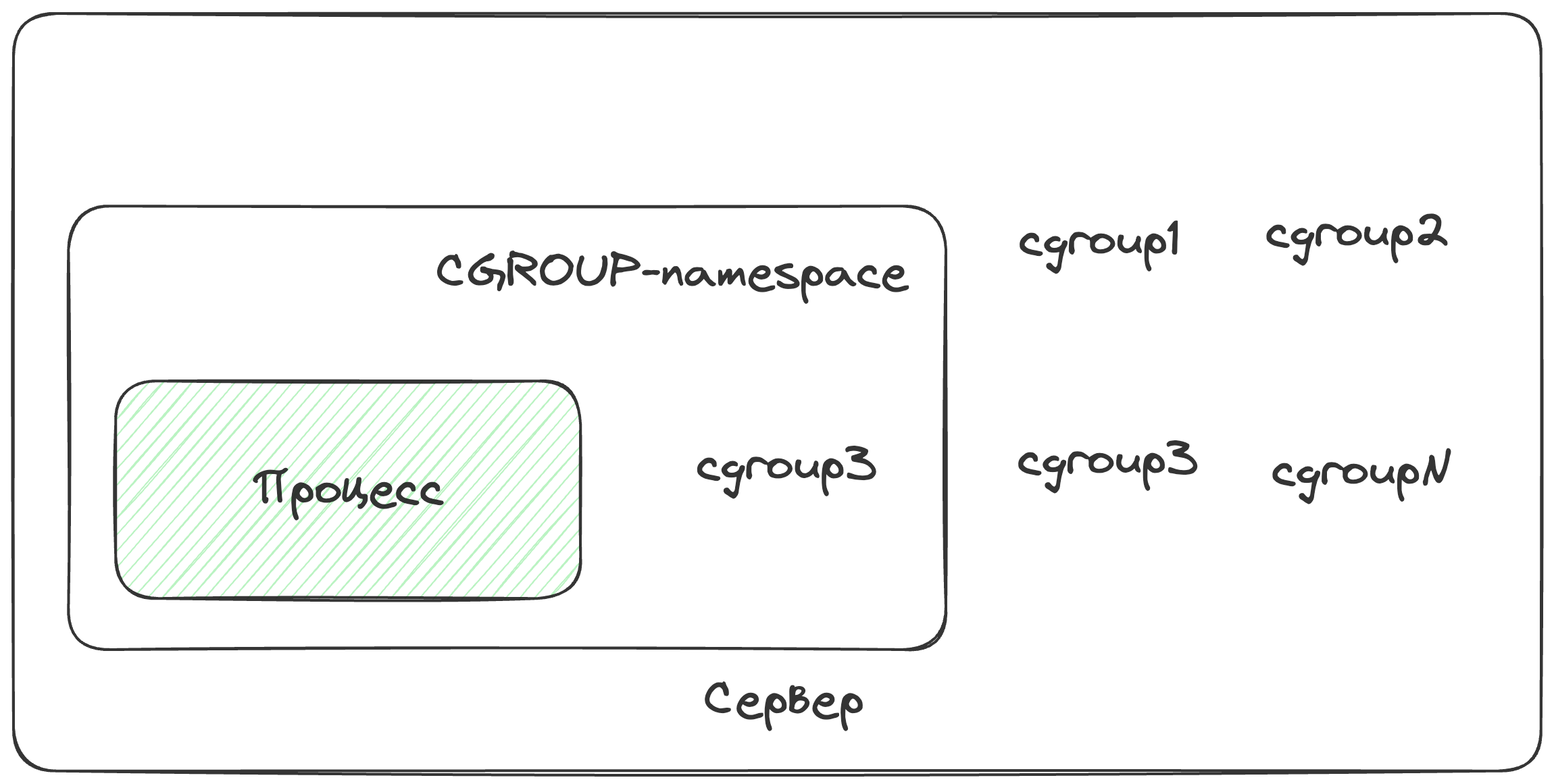
На это все. Вы прекрасны :)