
Kubernetes Garbage Collector. Как он работает
В рамках этой статьи мы рассмотрим, как работает Garbage Collector в Kubernetes. Данная статья была написана, когда мне пришлось разбираться в производительности Garbage Collector, а чтобы понять как его можно ускорить, сначала надо понять, как он работает. Для точного понимания мы будем запускать Garbage Collector локально в дебаг режиме, чтобы максимально ясно видеть как он работает и что делает.
Основное про Garbage Collector
В кластере Kubernetes у некоторых объектов есть Родитель, или же Владелец (то есть Owner). Классическая связка зависимых объектов, это Pod-ReplicaSet-Deployment. То есть у Pod‘a Owner - это ReplicaSet, с которым он связан. У ReplicaSet Owner - Deployment.
Давайте развернем простой Deployment и посмотрим у кого какой Owner прописался у созданных объектов
❯ kubectl create deployment demo --image nginx
❯ kubectl get pod demo-677cfb9d49-kk5rd -o jsonpath='{.metadata.ownerReferences}' | jq
[
{
"apiVersion": "apps/v1",
"blockOwnerDeletion": true,
"controller": true,
"kind": "ReplicaSet",
"name": "demo-677cfb9d49",
"uid": "80cb3139-6dec-49f1-a104-4ed1321539df"
}
]
❯ kubectl get replicasets.apps demo-677cfb9d49 -o jsonpath='{.metadata.ownerReferences}' | jq
[
{
"apiVersion": "apps/v1",
"blockOwnerDeletion": true,
"controller": true,
"kind": "Deployment",
"name": "demo",
"uid": "ccc4728a-41f8-4757-8605-2337382a1c89"
}
]
Зачем это нужно? Все довольно просто. Данная иерархия позволяет Kubernetes удалять лишние ресурсы в кластере в автоматическом режиме. Например, когда мы удаляем Deployment обычной командой:
❯ kubectl delete deployment demo
Все что происходит - это удаляется Deployment. Однако, когда мы удаляем Deployment мы так же ожидаем, что удалятся все его ReplicaSet‘ы и Pod‘ы. Именно этим и занимается gc. Он видит, что удалился Deployment и фоном запускает процесс убийства его зависимых ресурсов (то есть ReplicaSet‘ов). Далее он видит, что удалились ReplicaSet‘ы и удаляет уже его зависимые объекты - Pod‘ы.
Если вы хотите переопределить логику удаления ресурса и “ждать” пока все его зависимые ресурсы удалятся, тогда можно запустить команду delete с флагом –cascade=foreground. В таком случае команда удаления заблокируется и будет ожидать удаления всех зависимых объектов
Инициализируем среду
Начнем с того, что Garbage Collector - это один из компонентов Kubernetes Controller Manager‘a. А это значит, что мы довольно просто можем отключить его или же включить Controller Manager, в котором будет работать только GC. Делается это с помощью аргумента controllers. Давайте настроим среду, где мы будем запускать gc локально.
Для этого нам сначала нужно создать кластер Kubernetes, в котором будет выключен GC. Для быстрых локальных Kubernetes я использую KIND, который инициализирует ноды с помощью kubeadm, и, соответственно, мы можем сконфигурировать каждый компонент Kubernetes Control Plane с помощью InitConfiguration или ClusterConfiguration.
❯ cat <<EOF | kind create cluster --name without-gc --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
controllerManager:
extraArgs:
"controllers": "*,-garbage-collector-controller"
EOF
Проверим, что у нашего кластера не работает GC. Для этого создадим в кластере Deployment, потом удалим его и убедимся, что его ReplicaSet‘ы и Pod‘ы оставись жить.
❯ kubectl create deployment demo --image nginx
deployment.apps/demo created
❯ sleep 5
❯ kubectl get pods
NAME READY STATUS RESTARTS AGE
demo-6f84b74674-xr7v2 0/1 ContainerCreating 0 6s
❯ kubectl delete deployment demo
deployment.apps/demo deleted
❯ sleep 60
❯ kubectl get rs
NAME DESIRED CURRENT READY AGE
demo-6f84b74674 1 1 1 75s
❯ k get po
NAME READY STATUS RESTARTS AGE
demo-6f84b74674-xr7v2 1/1 Running 0 77s
Все как мы и ожидали. Теперь мы можем склонировать себе репозиторий Kubernetes и запустить Controller Manager c gc локально. В зависимости от используемой вами IDE, процесс может немного отличаться, но основное, что нужно сделать, это запусить ./cmd/kube-controller-manager/controller-manager.go с арументами:
--controllers=garbage-collector-controller
--kubeconfig=/Users/zvlb/.kube/config
--v=2
--leader-elect=false
--profiling=true
--authorization-always-allow-paths=/metrics,/debug/controllers/garbage-collector-controller/graph,/debug/pprof/*
Пройдемся по аргументам:
- controllers. Если в Controller Manager, который работает в kind мы отключили все, кроме gc, то в локально запускаемом Controller Manager’e мы запускаем ТОЛЬКО gc
- kubeconfig. Поскольку мы запускаем Controller Manager локально - ему нужно передать где ему искать kubeconfig с данными для подключения к Kubernetes
- v. Контролируем уровень логирования
- leader-elect. Мы запускаем один инстанс Controller Manager’а, которому не с кем конфликтовать и определять лидера. Отключаем этот функционал.
- profiling. Включаем go-профилировщик
- authorization-always-allow-paths. Выключаем необходимость авторизировать запросы на дебажный функционал
Как только мы его запустим, мы увидим, что ReplicaSet‘ы и Pod‘ы убитого ранее Deployment‘а успешно удалились!
Как работает Garbage Collector
Запустив локальный gc мы можем, наконец-то, посмотреть как он работает и что делает. В этой части будет много отсылок к коду и последовательный анализ того, что происходит.
Версия Kubernetes, код которой мы будем разглядывать код - v1.32.1
Первым делом Garbage Collector стартует. За это отвечает функция startGarbageCollectorController, в которой в goroutine запускается 2 основных процесса: Run и Sync. Run при запуске ждет когда выполнится логика в Sync’e, по этому сначала рассмотрим его и последовательно разберем.
Вообще у Sunc’a одна задача - следить, что для каждого ресурса в Kubernetes запущен свой Informer (в Garbage Collector‘e informer‘ы обернуты в дополнительную сущность - monitor), чтобы отслеживать события ADD/UPDATE/DELETE на каждый объект в Kubernetes. Основная задача Sync’a - это регистрировать monitor на каждый Resource (Pod/Deployment/любой *Custom Resource&) и следить, появились ли новые Resource, чтобы для них тоже зарегестрировать monitor. Происходит это следующим образом:
- Sync собирает информацию о всех Resource, которые есть в кластере
- Сравнивает полученный список ресурсов (newResources) с тем, который был получен при прошлом исполнении Sync’a (oldResources). Если они одинаковые - Sync завершается
- Если находятся какие-то отличия, запускается resync всех monitor’ов. Если monitor’s существовали ранее - ничего не изменится, однако, если появился новый ресурс (Custom Resource), он запустит для него monitor.
Это вся логика Sync’a) Однако надо немного заострить внимание на том, что такое monitor.
Monitor состоит из Informer Controller‘a и Informer Store‘a. Для Controller’a регистрируется handler, который вызывает определенную логику в зависимости от события, которое произошло с объектом (ADD/UPDATE/DELETE), за которым следит Informer. По факту на любое событие регистрируется event, который обрабатывает метод processGraphChanges, который в зависимости от события сделает 1 из 2:
- Если событие ADD или UPDATE анализируемый объект будет добавлен в граф, куда пропишутся связи объекта с его Owner‘ом.
- Если событие DELETE объект будет удален из графа и в очередь attemptToDelete будет передана информация о всех дочерних объектах, которые были определены ранее в графе.
Подробнее про то, как работают Kubernetes Informer’ы можно почитать в другой моей статье
Очередь attemptToDelete обрабатывается воркерами, которые инциализируется в Run функции. По факту все, что попадет в эту очередь будет отправлено на удаление из Kubernetes.
То есть если удалить Deployment произойдет следующее:
- Informer Controller, который настроен на Deployment‘ы увидит событие DELETE и передаст объект в очередь graphChanges
- processGraphChanges увидит, что в очереди graphChanges новое событие на удаление и отправит в очередь attemptToDelete все дочерние объекты нашего Deployment‘a, то есть его ReplicaSet‘ы
- Informer Controller, который настроен на ReplicaSet‘ы увидит событие DELETE и передаст объект в очередь graphChanges
- processGraphChanges увидит, что в очереди graphChanges новое событие на удаление и отправит в очередь attemptToDelete все дочерние объекты нашего ReplicaSet‘a, то есть его Pod‘ы
- Informer Controller, который настроен на Pod‘ы увидит событие DELETE и передаст объект в очередь graphChanges
- processGraphChanges увидит, что в очереди graphChanges новое событие на удаление и отправит в очередь attemptToDelete все дочерние объекты нашего Pod‘a, но поскольку таких нет - ничего не произойдет
Вот так и удаляются объекты из Kubernetes!
Немного тонкостей при работе Garbage Collector
Graph Debug
Запуская gc и включив его профилировку (агрумент --profiling=true) и выключив авторизацию на путь /debug/controllers/garbage-collector-controller/graph (аргумент --authorization-always-allow-paths=/debug/controllers/garbage-collector-controller/graph) мы можем в любой момент времени достать из gc весь сформированный граф и проанализировать связи, которые в нем сформировались.
Запустив локалько Controller Manager c gc по пути https://localhost:10257/debug/controllers/garbage-collector-controller/graph - вы увидите граф. Однако в таком формате ничего не понятно. Можно выгрузить граф и перевести его в формат SVG
curl -k https://localhost:10257/debug/controllers/garbage-collector-controller/graph | dot -T svg -o gc.svg
Сам файл:
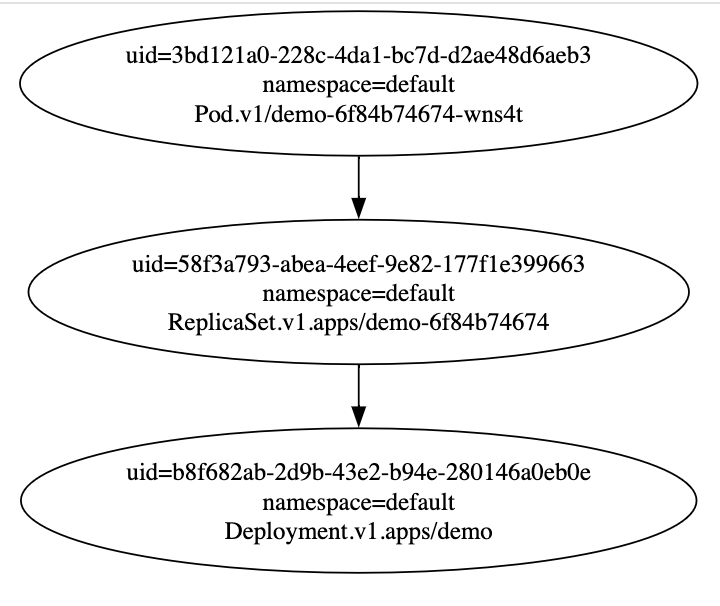
Долгий прогрев
Если у вас много, действительно МНОГО, ресурсов в кластере Kubernetes, может случится неприятная ситуация. Garbage Collector не может начать удалять ресурсы из Kubernetes, пока не сформировался Граф. При формировании графа gc берет ВСЕ объекты из кластера Kubernetes, на что может уйти время. А это значит, что при рестарте gc, или при смене лидера возможна ситуация, когда в Kubernetes не удаляются дочерние ресурсы из-за того, что Garbage Collector занят формированием графа, а не удалением объектов.
На самом деле ситуация рестарта или смены лидера у Controller Manager’a - редкая и обычно проблем не вызывает, однако если вам необходимо улучшить производительность, можно подкрутить следующие параметры --kube-api-qps, --kube-api-burst и --concurrent-gc-syncs
На это все. Вы прекрасны :)